
跟着AI技巧的快速发展,越来越多的产物司理运行念念考如何转型为AI产物司理。关联词,AI念念维与传统的产物念念维和用户念念维有何不同?如何从数据起程,构建以栽培出产力为办法的产物遐想逻辑?本文从赫布表面起程,真切探讨了用户念念维、产物念念维与AI念念维的异同白虎 女優,并详实解读了AI念念维的四大身分:大数据、模子、算力和业务模式。
近期围绕“如何转型AI产物司理”的话题,提前进行了一些准备责任,但有一个问题,长期绕不外去。
什么是AI念念维?它与产物念念维、用户念念维有何异同之处?
什么是AI念念维?
无论用户念念维、产物念念维,或是AI念念维,王人属于念念维,而不同岗亭/变装的各别开头即是念念维样子。
是以,今天共享“如何转型AI产物司理”的念念维篇,从念念维的角度,探索不同念念维样子的异同点。
01 赫布表面:东说念主脑的学习机制
我们野心之前,先粗浅学习一下赫布表面——无论是用户念念维、产物念念维,照旧AI念念维,基础王人是赫布表面的学习机制。
赫布表面(Hebbian Theory)是由加拿大神态学家唐纳德·赫布(Donald Hebb)于1949岁首次冷落的神经科学表面,主要描述了突触可塑性的基本机制。
赫布表面标明:东说念主类大脑中有多个神经元,当一个神经元(前突触细胞)捏续或重迭刺激另一个神经元(后突触细胞)时,两个神经元之间的传递着力加多,变成一个细胞回路,大脑就会记取这两个事物之间的研究。
比如当你听见《婚典进行曲》时,你就会意想我方活某个一又友的婚典;
当你听见“可乐”时,你就会意想“适口可乐”;
当你看到一个表面时(比如赫布表面/牛顿力学等),你就会想起它背后所抒发的意旨兴致以及表面冷落者(前提是你经过捏续或重迭的研究刺激)。
这种机制即是“赫布学习”机制,它是东说念主脑的学习机制,亦然当今AI边界的神经相聚的学习机制。
用户念念维 VS 产物念念维 VS AI念念维
用户念念维是以问题为中枢的念念考样子,它是一种理性念念维。
东说念主们是从训戒中受到刺激时,东说念主脑就会像赫布表面一样,学习到研究事物之间的研究,变成我方的默契或偏好——以至是法例(若是它填塞正确且通用的话)。
训戒会改动东说念主脑的回路,当下次际遇新问题时,东说念主们就通过所变成的默契/偏好等,快速分类问题,以至作念出判断。
比如每当电梯行将关门时,风俗了国内的电梯遐想,你会下意志伸手或腿窒碍,它会立即关门,但若是放洋后,某些电梯遐想时不除名此规定,可能就会将你夹伤。
概况,你风俗了A系统的使用,它不错挂牵你每次的导出模版,而换到B系统后,导出无挂牵,需要你每次王人自行遴选模板,你就会相配恼火。
这即是用户念念维的特色——以问题为原点,和洽训戒所变成的默契或偏好后,际遇新问题时会以此进行判断与决策。
我们再来看产物念念维白虎 女優。
产物念念维是以已毕为中枢的念念考样子,它是一种(相对)理性念念维。它是以放弃信息不合称问题,栽培信息传递后果为办法进行产物遐想。
比如QQ/微信栽培信息传递后果,处治远距离及时交流同样的问题;淘宝/京东等栽培商品信息的传递后果,买互市品流转的所有中间智商,缩小两边的老本等。
但它的基础亦然赫布学习表面,与用户念念维的各别点是它在保留默契/偏好的基础之上,栽培至步履论的进度,确保它更具有通用性。
比如用户跟你提需求说:“你们系统王人是月度报表,而莫得周报以及逐日工时情况,这个需求提了很久,你们什么时间作念?”
你会基于步履论——需求是1,决议是0——先弄了了用户的需求布景与诉求,再念念考处治决议;
你也会基于训戒——用户提的是处治决议,而不是需求。它的需求是否可规定化或系统化——比如如何折柳每周,逐日工时是否有打算公式?
当了解了了需求与规定后,你还需要探讨进入产出比与优先级,最终进行决策。
它跟用户念念维的最大各别就出来了——用户念念维是问题念念维(即它是问题,且得当默契/偏好,就需要处治);产物念念维是已毕念念维(即需求合理,可规定化,优先级高,进入产出合理。当问题逐一得当时,才需要处治)。
终末,我们来看AI念念维。
用户念念维与产物念念维的开头,王人是基于过往训戒,通过所资格的事情变成事物之间的关联联系。
但有东说念主算计过,东说念主脑通过神经元来激活阅读相连的信息速率是每天1MB傍边,而产生的信息速率却是每天2.5EB。换句话说,每天所产生的信息是你大脑所能处理信息的的2500亿倍。
当你看到这个数据差之后,可能就相连了东说念主脑的局限,而这种局限性却是AI的本事场所。
AI念念维是以数据为中枢,以栽培出产力为办法进行产物遐想。
它是一种(统统)理性念念维——它以至不热苦衷物的因果联系,而更贯注的是关联联系。
比如淘宝、京东等电商平台的首页保举产物,早先是由专科的运营东说念主员,决策哪些选品或步履更能受到用户的精良,跟着用户范围的激增以及用户的各种化后,再专科的运营东说念主员,也无法精确瞻望每个用户的喜好——产物念念维失效,而AI念念维运行流露价值。
强奸因为产物念念维是基于步履论判断一个(或多个)需求的合理性,却无法判断海量用户的需求各别和合理性,以及可能堕入盲目跟进竞品的羊群效应之中——羊群中一朝有一只羊先行,其他羊就会不假念念索地跟进。
比如送外卖,若是仅探讨一个外卖员配送指定数目的外卖(如5份),则外卖员我方就不错灵验遐想最好旅途,而若是要探讨雨后春笋的外卖员以及数以百亿份的外卖,则非东说念主力范围场所(不管是外卖员,或“专科”的产物司理)。
同期,从责任内容看,互联网产物司理的属于可视化责任(面向具体用户和需求进行页面化产物遐想,处治信息后果问题),而AI产物司理属于不可视化的责任(面向无数看不见的用户进行数据化处理与决策,处治出产力问题)。
比如ChatGPT/DeepSeek等产物,若是以互联网产物视角看,它们相配粗浅,可看见的即是一个输入框和聊天界面,而从AI产物视角看,它们所依赖的海量的数据的采集、预考试、微调等,通过模子化的样子,已毕了通用化AI产物简直立,经过中的多数责任王人属于“不可见”责任。
02 AI念念维的四大身分
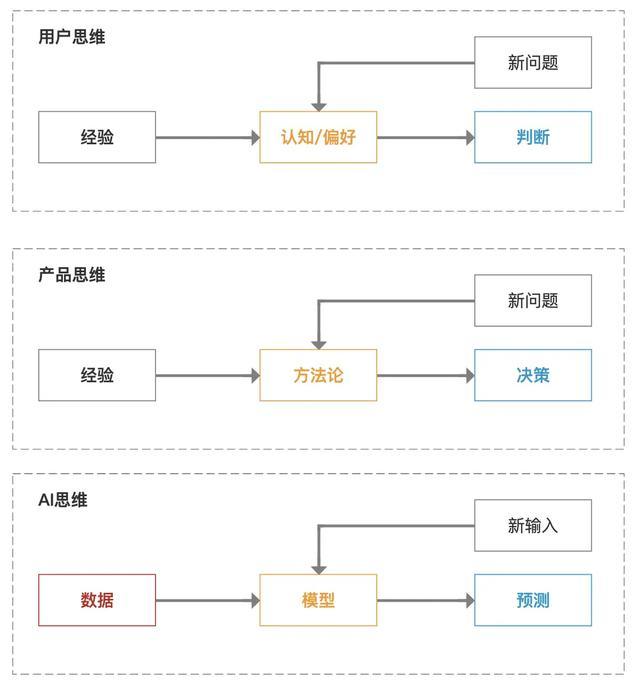
用户念念维的四大身分是:问题、效用、老本、收益;
产物念念维的四大身分是:用户、需求、处治决议、价值;
AI念念维的四大身分是:大数据、模子、算力、业务模式。
第孤单分是大数据。AI念念维是从数据起程,通过数据采集、清洗、分类、回想、聚类等样子,对现存海量数据进行分析和判断,学习内在法例后,对新数据/新问进行瞻望。
它与产物念念维是从用户起程,依然发生了践诺的不同,导致若是想转型AI产物司理,必须从用户念念维转向数据念念维,从可视化界面转为“不可见”的数据,从以一个具象的用户转向不具象的数据。
第二身分是模子。东说念主脑是由大脑的神经元之间的重迭讨好,产惹事物之间的研究,从而作念出决策,而AI的践诺,亦然对大脑的“师法”和越过。
东说念主脑的决策模子是神经相聚,而AI决策是以东说念主工神经相聚为基础的模子。
以深度学习为例。它的基础是东说念主工神经相聚,而要津的模子是卷积神经相聚(即CNN)和轮回神经相聚(即RNN)。
卷积神经相聚是在感知机三层结构(即输入层、荫藏层、输出层)的基础上,加多了多个层级(即输入层、卷积层、池化层、全讨好层),让每个神经元分别认真不同的任务,最终可已毕单一事务的识别(比如图像识别、物体识别等)。
比如输入层是对图像进行预处理,缩小图像识别的维度,卷积层的神经元是认真提真金不怕火图像中的某个局部的要津特征点(比如提真金不怕火小猫的头部、体魄等),池化层是对图像进行压缩降维,减少打算量,全讨好层是认真将前边所有层的数据,讨好组合起来(比如将小猫头部、体魄、当作等局部组合起来),然后识别出来物体(比如如它是一只小猫)。
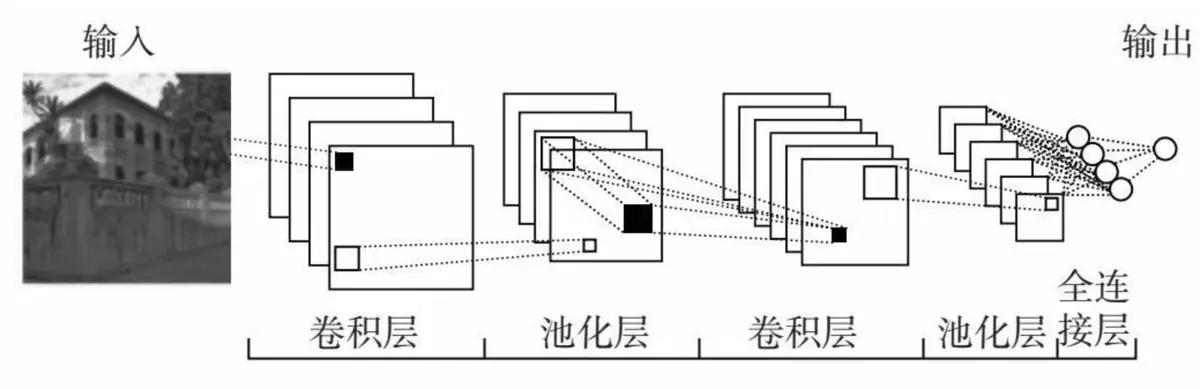
卷积神经相聚识别的是寂然的事件(比如它相配适用于图片识别),却不成进行连气儿性的识别或瞻望。
比如“今天共享的内容相比多,但它们王人是对于”。
若是要对这句话进行填空,研究高下文后,应该不错赢得谜底(即念念维样子或AI),但卷积神经相聚作念不到,而轮回神经相聚则不错。
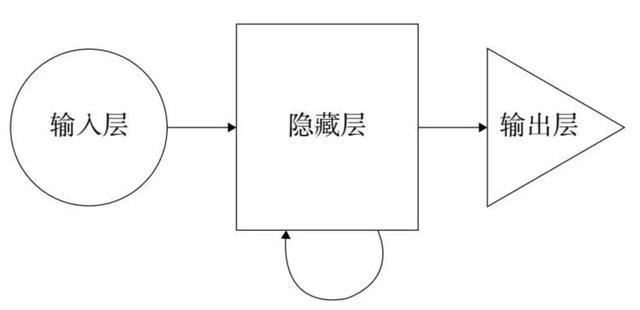
轮回神经相聚“唯一”三层:输入层、荫藏层、输出层,但其荫藏层里面是轮回反复的,它不错收受新输入信息,同期自轮回网罗上一次的内容,它就具备了挂牵、讨好高下文的本事——非凡适用于当然话语翻译、语音识别等边界。
第三身分是算力。大数据的处理与瞻望,可已毕的中枢就在于算力。我们常见的算力系统是电脑、手机、东说念主脑等,它们是不错提供一部分算力,但对于AI来说,远远不够。
它需要大范围的打算机集群,将成百上千的算力系统讨好起来,变成一个打算集群,才不错进行大范围运算。比如谷歌实验室的谷歌大脑即是将16000台打算器讨好在一说念,才能已毕渊博的自主学习。
固然,除了打算器集群外,算力自身还需要GPU架构,它不错更好的已毕深度学习模子的运算,这亦然英伟达成为AI期间的“最好送水东说念主”的原因场所。
第四身分是业务模式。无论是产物念念维,照旧AI念念维,最终王人要落地在一个场景上,这亦然互联网产物司理与AI产物司理最大的相似之处。
比如金融边界,之前的放贷模式是依赖东说念主工进行假贷东说念主得征信走访责任,若是精良则披发;不然就不披发。这种模式的后果低下,老本高,无法例模化,而这即是AI的最好落地愚弄场景之一。
再比如教悔行业。从早期的拍照搜题+双师大班网课,到当今的东说念主工智能学习机、东说念主工智能教辅等的落地愚弄,王人是在AI的加捏下,用更高效、更低老本的样子,再行完成了对场景的重构。
非凡声名
作为又名学习者白虎 女優,骨子裁习和“借用”了最近读到的一些前辈的竹素里的部分案例与内容(尤其是丁磊真挚所著的《AI念念维:从数据中创造价值的真金不怕火金术》)。